
Apache PDFBox is a widely-used open-source Java library highly regarded for its extensive capabilities in manipulating PDF files. This powerful tool provides developers with a range of functionalities, such as reading and writing PDFs, extracting text and images, managing fonts, accessing metadata, and encrypting and decrypting PDF files.
With Apache PDFBox, developers can efficiently handle various tasks related to PDF document processing within their Java applications.
I. Create Interactive or Fillable PDF Form
First and foremost, we will clarify the distinction between interactive or fillable PDF forms and standard PDFs, highlighting key differences between them.
- Interactive or fillable PDF forms let users input data directly into fields, including text boxes, checkboxes, radio buttons, and drop-down menus. After completing the form, users can save or print the document.
- Standard PDFs contain static content such as text, images, and graphics but does not include interactive form fields. Users cannot input data directly into a normal PDF document; instead, they can only view or print the content.
The next question is: How can we create interactive or fillable PDF forms? A user-friendly interface allows you to design and add fields like text boxes, checkboxes, radio buttons, and dropdown menus to your PDFs easily.
You can also consider checking out some other popular alternatives besides Adobe Acrobat for creating interactive or fillable PDF forms.
- PDFescape
- Nitro Pro
- Foxit PhantomPDF
- PDFelement
- LibreOffice Draw
Let us try using the PDFescape online website, which supports free PDF creation. Then, you can create a sample as described below:
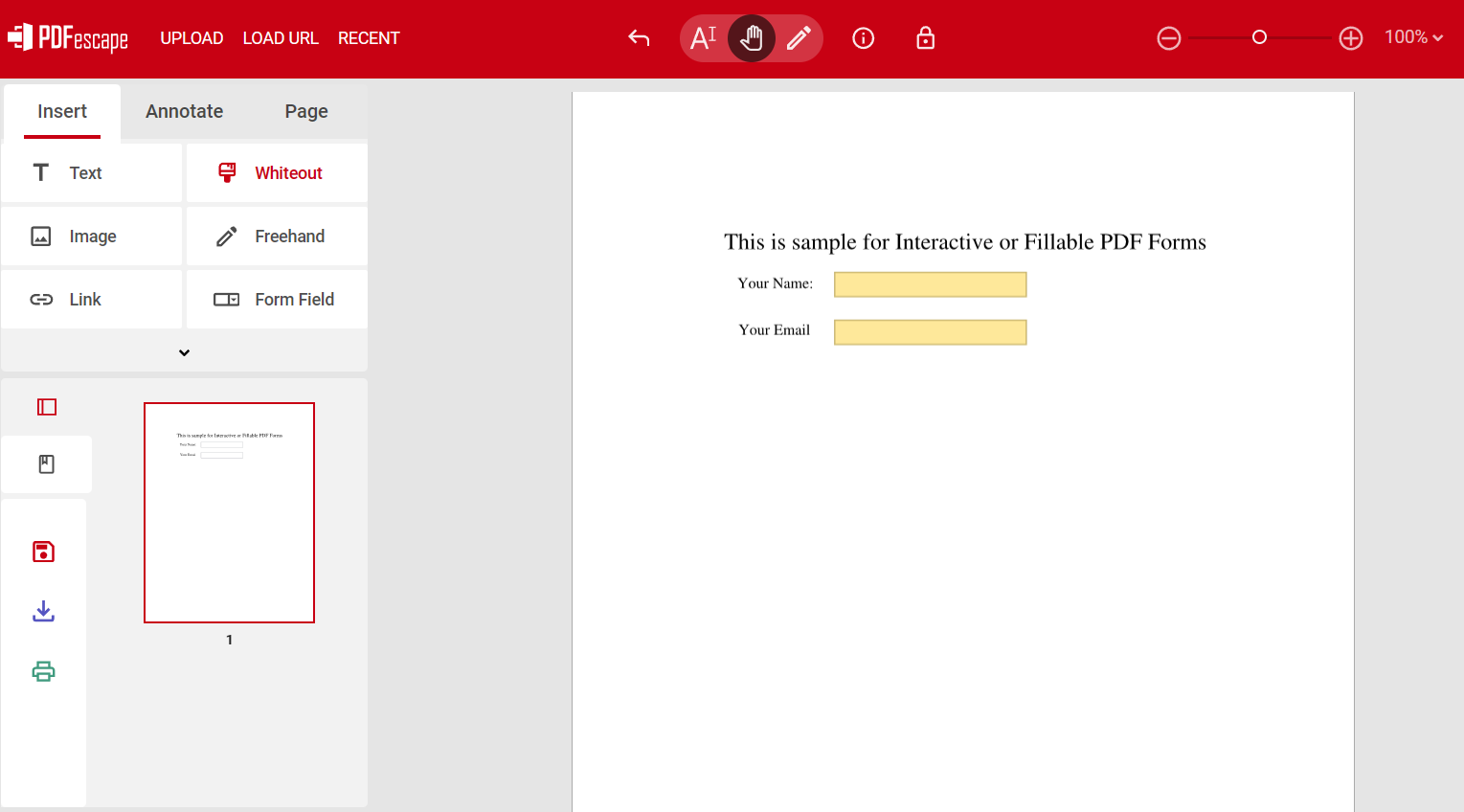
Next, click the `Download` button to obtain your modified interactive PDF forms, which you can then open using Foxit PDF Reader or web browser.
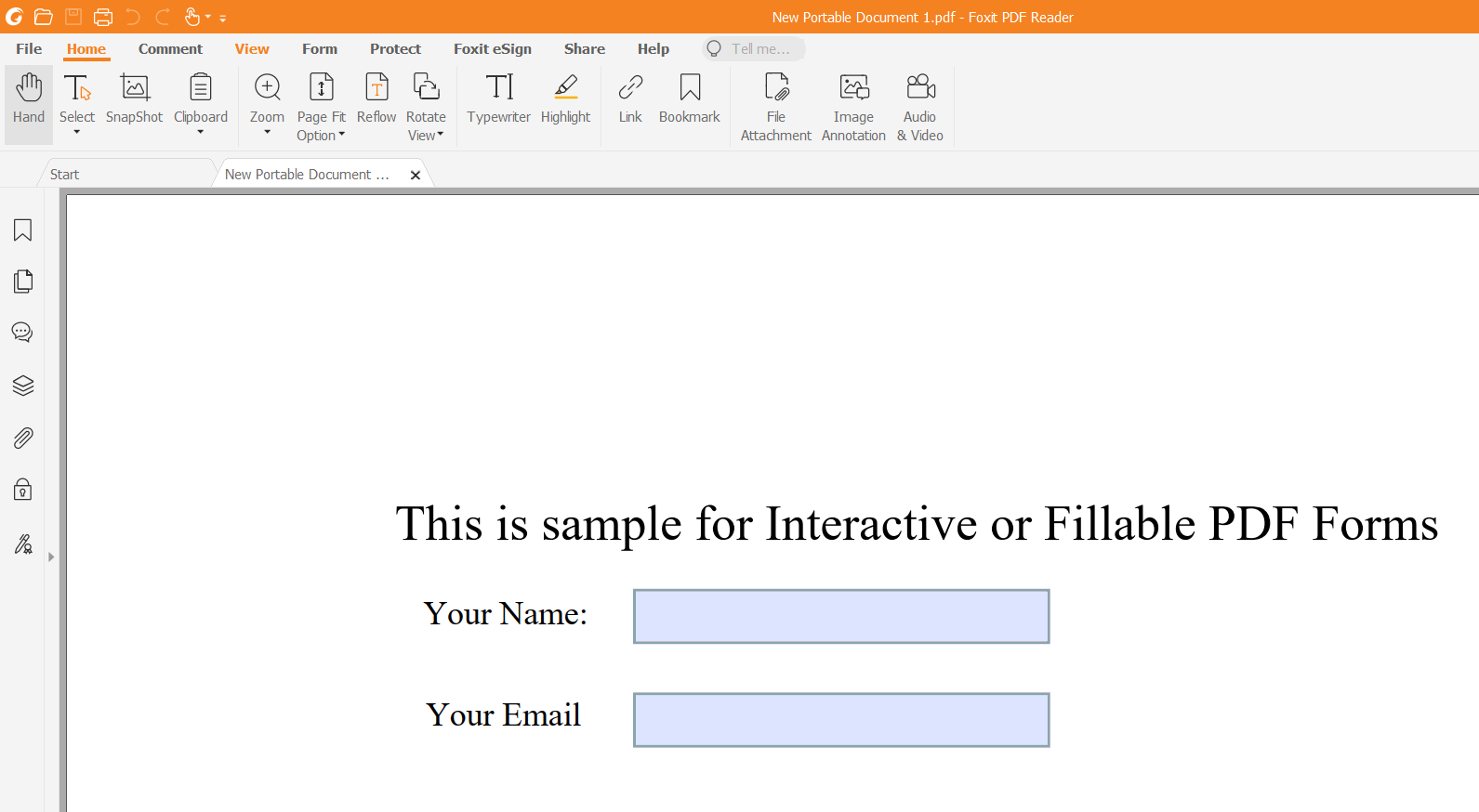
In the following section, we will use the capabilities of Apache PDFBox to perform basic tasks such as writing to PDF files, reading PDF templates (including interactive or fillable PDFs), and dynamically populating data onto interactive PDF forms.
II. Create Interactive Fillable PDFs with AEM Forms Designer
AEM Forms Designer supports designing fillable PDF forms. It allows you to create, manage, and deploy interactive and fillable PDFs with elements like text fields, checkboxes, and radio buttons. Log in to your Adobe Cloud account authenticated with your organization.
Navigate to Software Distribution and select AEM as a Cloud Service. Use the keyword `Designer` to search for and download the AEM Forms Designer tool for your operating system.
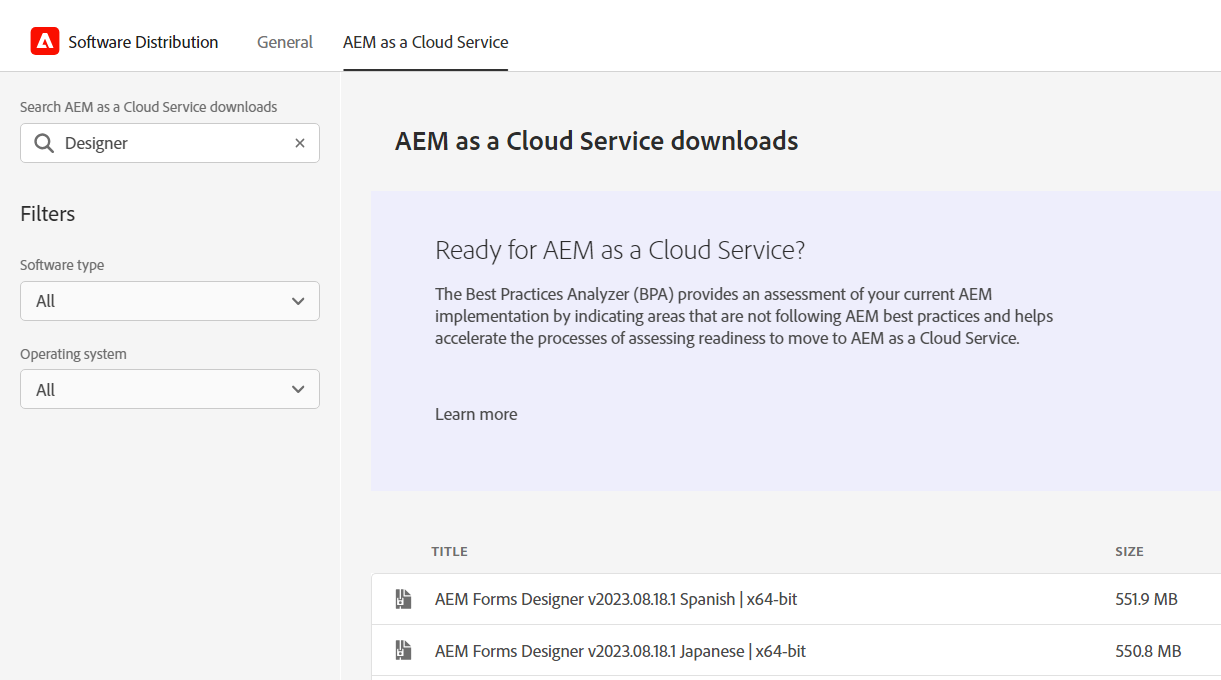
Open the AEM Forms Designer tool and create fillable PDF form. In Getting Started, choose Based on a template and select the Contact Information template.
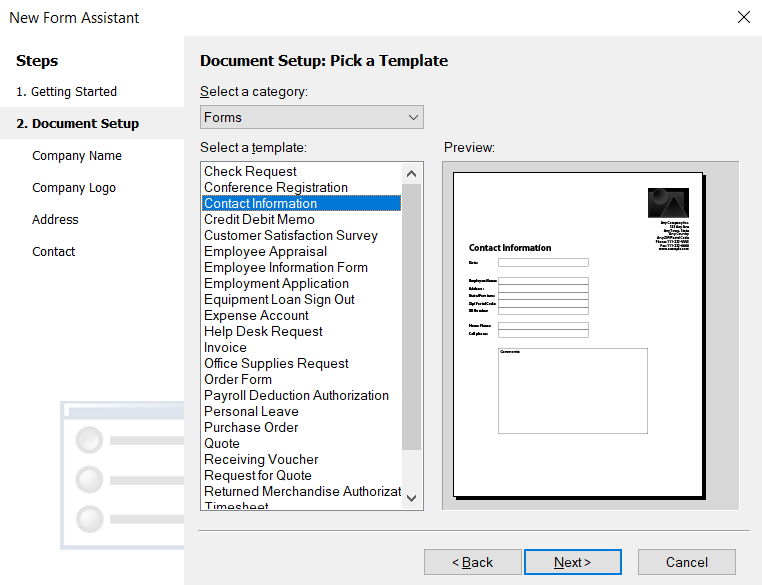
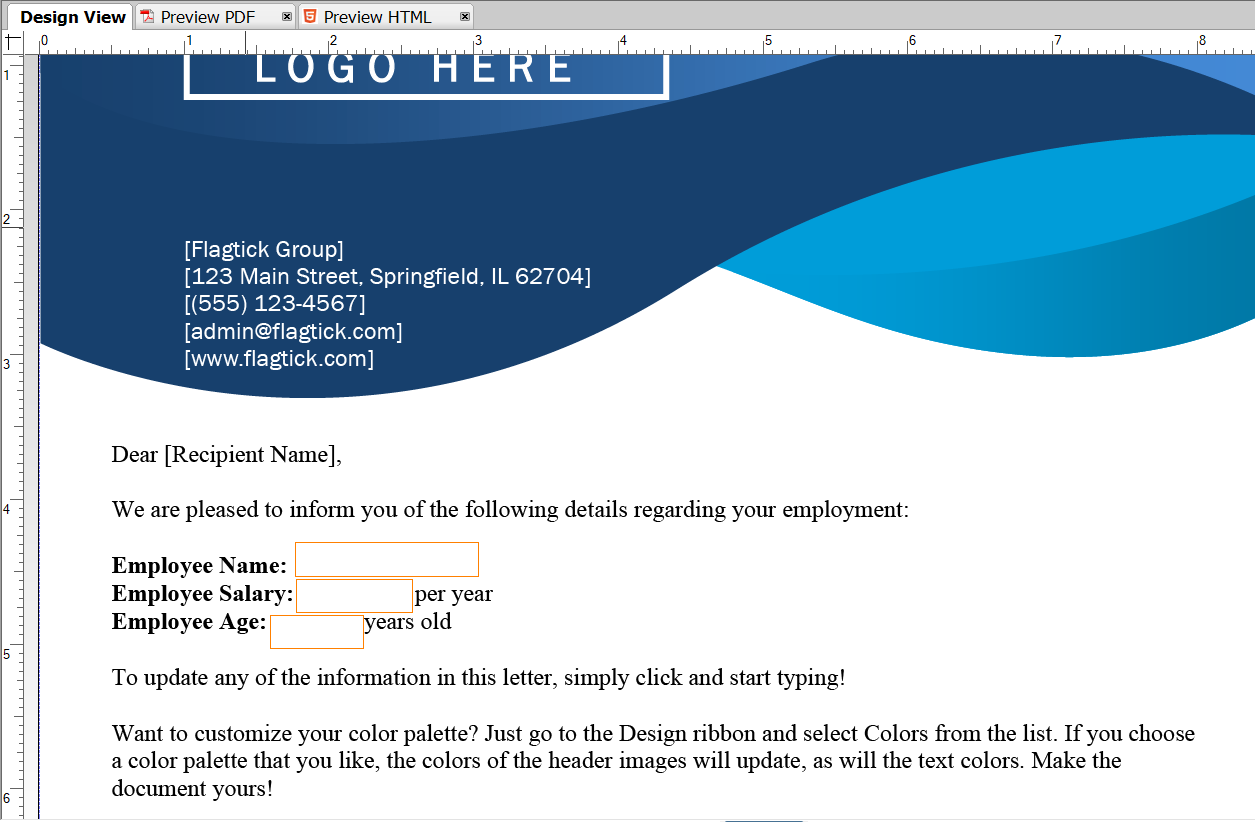
There are four modes to view your template in AEM Forms Designer: Design View, Master Pages, Preview PDF, and Preview HTML. Look at the right sidebar, which includes the Object Library with items like Button, Circle, Date Field, and Decimal Field,... You can use these to design interactive PDF form fields.
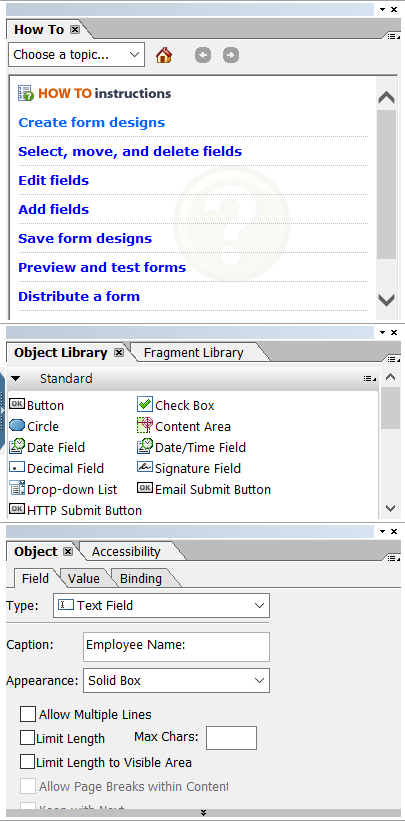
In the Object tab, you can see Field, Value, and Binding. When you click any form field in the Design View screen, you will retrieve information such as Type of Object, Caption, and Appearance. For example, Employee Name.
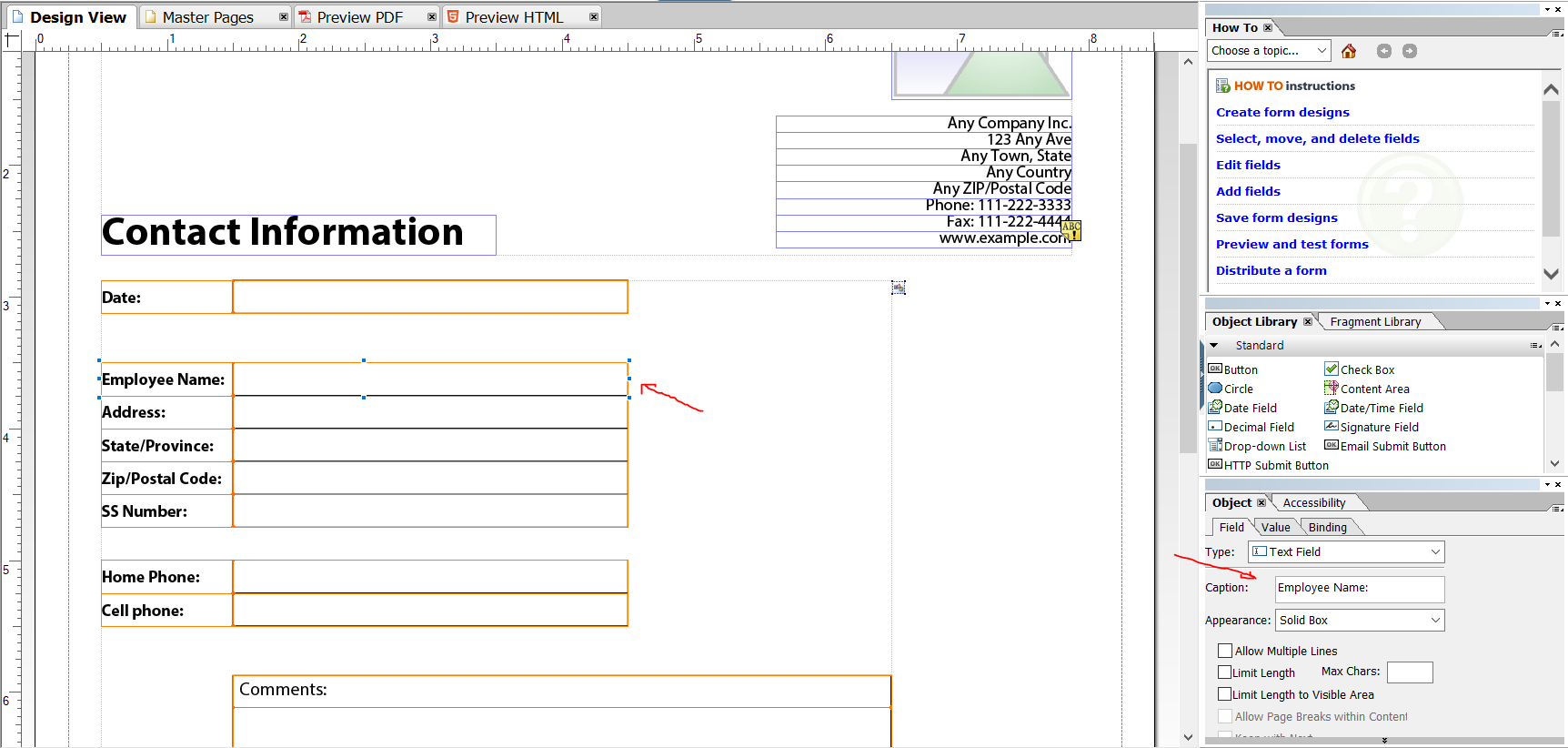
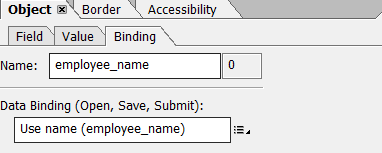
Go to the Binding section to set up an ID for each form field, allowing you to bind values directly from Apache PDFBox or any other supported library.
Modify the PDF template as shown below, remove any unused form fields, and save it as a PDF file.
You can use Microsoft Word to design and save documents as PDF files. This allows you to create templates for specific types of bills, such as utility bills, medical bills, invoice bills, rent bills, tax bills, purchase bills, and loan bills.
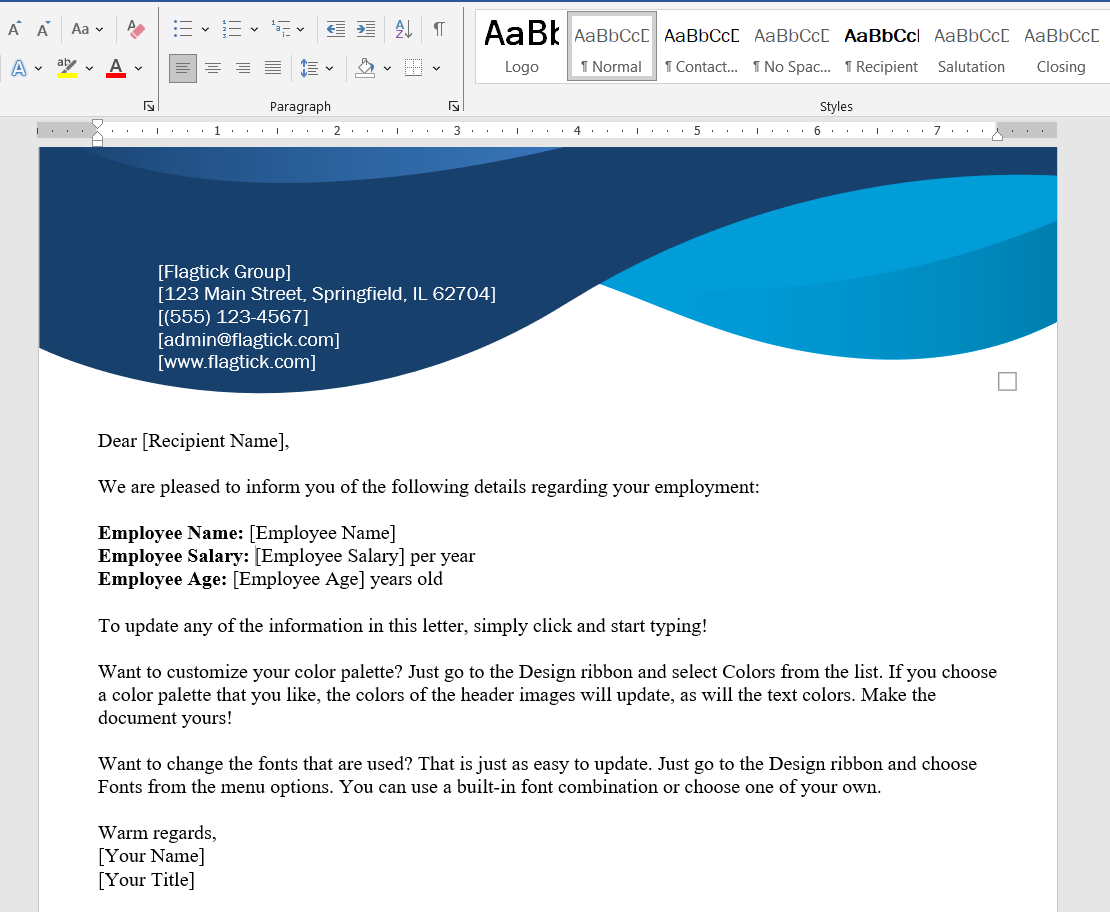
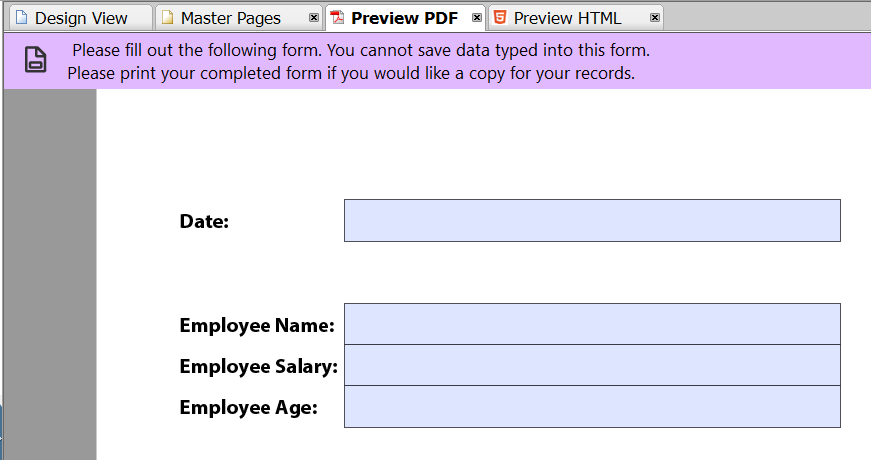
Please create template with blank fields for Employee Name, Employee Salary, and Employee Age. Export this template as PDF file to prepare it for injecting form fields using AEM Forms Designer.

Drag and drop the PDF template into the AEM Forms Designer tool, then proceed to add form fields to the template.
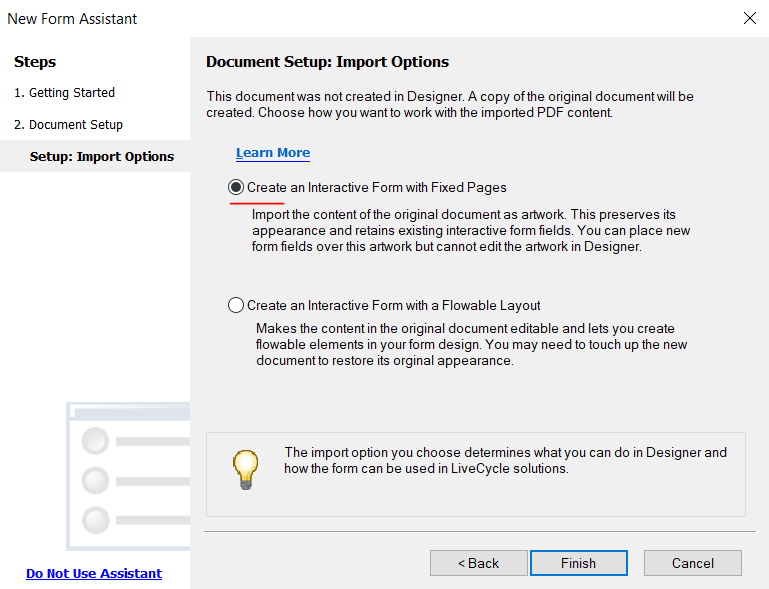
Please select `None` for the border option. After making this change, you should see the results as shown below:
In the next section, we will analyze data from REST API example and map it to PDF using binding IDs designed in the AEM Forms Designer tool.
III. Use Apache PDFBox to Generate PDF file
First and foremost, let set up Java project with script demonstrating PDF generation, SLF4J logging, and error handling in PDF service implementation. Visit here for more information. In Java application, `application.properties` supports dynamic PDF templates by storing template configurations, allowing easy management and switching of templates without code modification.
Here is step-by-step workflow for generating PDF from template with apache PDFBox for each step:
1. Load PDF Template:
Assume that you identify the tax year to get the suitable template based on the `application.properties` file. Here is an approach to detect and implement the necessary code:
» App.java
public class App {
private static final Logger LOGGER = LoggerFactory.getLogger(App.class);
private static final Map<String, String> templateTaxes = new HashMap<>();
public static void main(String[] args) {
try (InputStream input = App.class.getClassLoader().getResourceAsStream("application.properties")) {
if (input == null) {
LOGGER.error("Sorry, unable to find application.properties");
return;
}
Properties prop = new Properties();
prop.load(input);
String templates = prop.getProperty("templates");
if (templates != null && !templates.isEmpty()) {
for (String kv : templates.split(",")) {
String[] a = kv.split(":");
if (a.length == 2) {
templateTaxes.put(a[0], a[1]);
}
}
// TODO
LOGGER.info("Templates loaded successfully: {}", templateTaxes);
} else {
LOGGER.warn("No templates found in application.properties");
}
} catch (IOException e) {
LOGGER.error("Error loading application.properties", e);
}
}
}
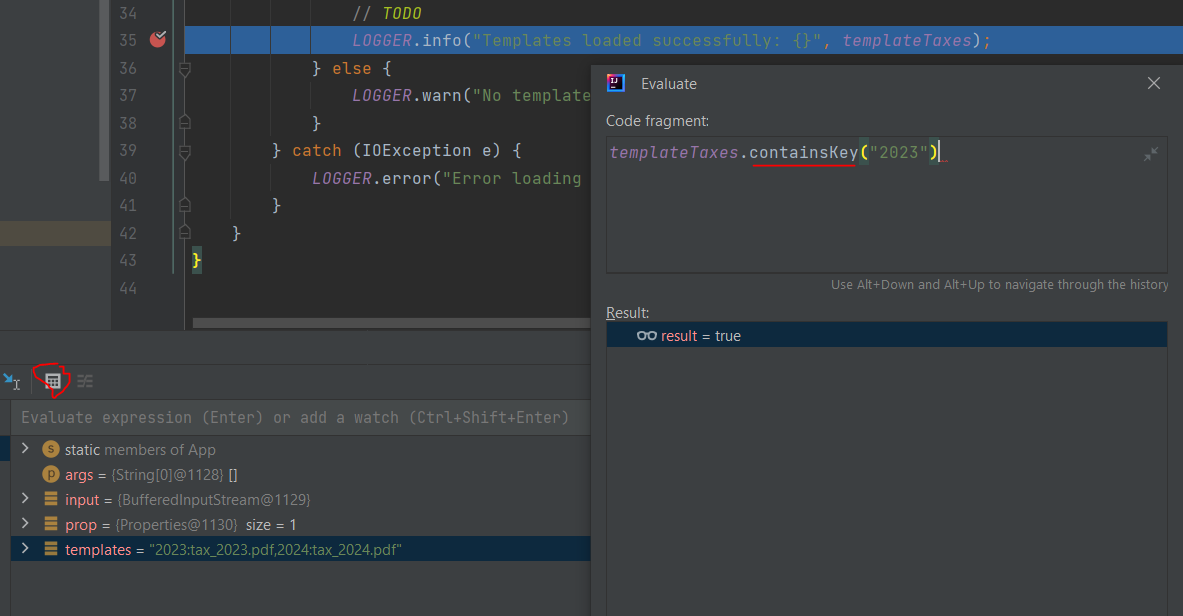
With the `templateTaxes` declared as HashMap, you can first check if the given year exists using the containsKey method and then retrieve the appropriate template using the get method.
if (templateTaxes.containsKey(tax_year)) {
template = templateTaxes.get(tax_year);
}
Note: You can place debug statements at the //TODO comments to explore methods involving the HashMap.
2. Fetch Data from API: Here are several approaches for making HTTP requests in Java. You can reference the code snippet provided here for implementation details.
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpGet request = new HttpGet("https://dummy.restapiexample.com/api/v1/employee/1");
HttpResponse response = httpClient.execute(request);
HttpEntity entity = response.getEntity();
String result = EntityUtils.toString(entity);
You can use an online JSON viewer tool to view the content of the response from the URL https://dummy.restapiexample.com/api/v1/employee/1. Once you have the data, you can design an interactive or fillable PDF form based on the information.
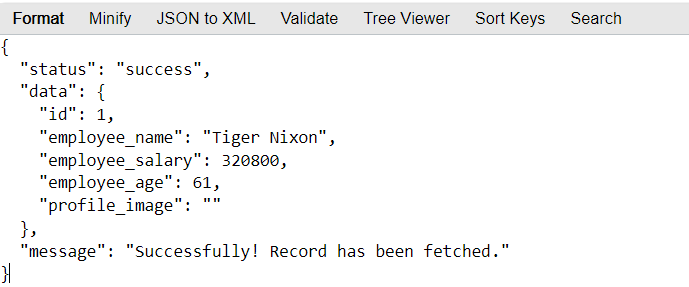
We will use ObjectMapper and StdDeserializer to extract the JSON response and save the information, such as `employee_name`, `employee_salary`, and `employee_age`, into HashMap. Let us install the dependencies needed to use Object Mapper.
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.13.3</version>
</dependency>
» `EmployeeDeserializer.java`
package com.app.flagtick.deserializer;
import com.fasterxml.jackson.core.JsonParser;
import com.fasterxml.jackson.databind.DeserializationContext;
import com.fasterxml.jackson.databind.JsonDeserializer;
import com.fasterxml.jackson.databind.ObjectMapper;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
public class EmployeeDeserializer extends JsonDeserializer<Map<String, Object>> {
@Override
public Map<String, Object> deserialize(JsonParser jsonParser, DeserializationContext deserializationContext)
throws IOException {
Map<String, Object> employeeData = new HashMap<>();
ObjectMapper mapper = new ObjectMapper();
Map<String, Object> response = mapper.readValue(jsonParser, Map.class);
Map<String, Object> data = (Map<String, Object>) response.get("data");
employeeData.put("employee_name", data.get("employee_name"));
employeeData.put("employee_salary", data.get("employee_salary"));
employeeData.put("employee_age", data.get("employee_age"));
return employeeData;
}
}
Then, call `EmployeeDeserializer.java` to extract JSON data from the REST API in the `App.java` file.
...
ObjectMapper mapper = new ObjectMapper();
SimpleModule module = new SimpleModule();
module.addDeserializer(Map.class, new EmployeeDeserializer());
mapper.registerModule(module);
Map<String, Object> employeeData = mapper.readValue(result, Map.class);
// Print the extracted information
System.out.println("Employee Name: " + employeeData.get("employee_name"));
System.out.println("Employee Salary: " + employeeData.get("employee_salary"));
System.out.println("Employee Age: " + employeeData.get("employee_age"));
Instead of using SimpleModule, avoid it and directly deserialize the response into custom class that matches the structure of the JSON data and visit here for more approaching way. Use the modified PDF you designed in the AEM Forms Designer tool as an example. The fields in the PDF form are mapped to the following binding IDs:
- Employee Name: employee_name
- Employee Salary: employee_salary
- Employee Age: employee_age
3. Fill PDF Form Fields: You can use Apache PDFBox in your Java project to work with PDF documents. Set up Apache PDFBox dependencies in the `pom.xml` file.
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>3.0.0-alpha2</version>
</dependency>
Using PDFBox 3.x.x (alpha or beta) includes the `fontbox` dependency. For specific needs of `fontbox`, add it as follows:
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>fontbox</artifactId>
<version>3.0.0-alpha2</version>
</dependency>
Let us use the following script to log information about each form field in the PDF document, including its fully qualified name, partial name, and field type.
// TODO
String template = null;
if (templateTaxes.containsKey("2023")) {
template = templateTaxes.get("2023");
}
System.out.println("Template: " + template);
try {
URL res = App.class.getClassLoader().getResource(template);
if (res == null) {
System.out.println("Resource not found: " + template);
return;
}
File file = Paths.get(res.toURI()).toFile();
PDDocument document = Loader.loadPDF(file);
try {
PDAcroForm acroForm = document.getDocumentCatalog().getAcroForm();
if (acroForm != null) {
PDFieldTree fieldTree = acroForm.getFieldTree();
Iterator<PDField> var26 = fieldTree.iterator();
while (var26.hasNext()) {
PDField field = (PDField) var26.next();
String fullyQualifiedName = field.getFullyQualifiedName();
String partialName = field.getPartialName();
String fieldType = field.getFieldType();
System.out.println("Field name: " + fullyQualifiedName);
System.out.println("Field Partial Name: " + partialName);
System.out.println("Field type: " + fieldType);
System.out.println("Field class: " + field.getClass().getSimpleName());
}
acroForm.flatten();
} else {
System.out.println("The PDF does not contain any form fields.");
}
} finally {
document.close();
}
} catch (IOException | URISyntaxException e) {
System.out.println("Exception: " + e.getMessage());
e.printStackTrace();
}
After running the script, you will see the log output as shown below.
Template: tax_2023.pdf
Field name: topmostSubform[0]
Field Partial Name: topmostSubform[0]
Field type: null
Field class: PDNonTerminalField
Field name: topmostSubform[0].Page1[0]
Field Partial Name: Page1[0]
Field type: null
Field class: PDNonTerminalField
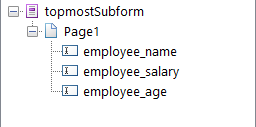
Field name: topmostSubform[0].Page1[0].employee_name[0]
Field Partial Name: employee_name[0]
Field type: Tx
Field class: PDTextField
Field name: topmostSubform[0].Page1[0].employee_salary[0]
Field Partial Name: employee_salary[0]
Field type: Tx
Field class: PDTextField
Field name: topmostSubform[0].Page1[0].employee_age[0]
Field Partial Name: employee_age[0]
Field type: Tx
Field class: PDTextField
We need to ensure that each key in employeeData is mapped with the prefix `[0]` to satisfy the condition required for adding data correctly to the PDF file.
HashMap<String, String> transformedEmployeeData = new HashMap<>();
for (Map.Entry<String, Object> entry : employeeData.entrySet()) {
String originalKey = entry.getKey();
String newKey = originalKey + "[0]";
transformedEmployeeData.put(newKey, String.valueOf(entry.getValue()));
}
employeeData.clear();
employeeData.putAll(transformedEmployeeData);
Compared to the design in the AEM Forms Designer tool, it will look like this.
Assign the value from `employeeData` to the field if fieldType is text field and the key exists in `employeeData`.
if (fieldType != null && fieldType.equals(FT_TEXT_FIELD) && employeeData.containsKey(partialName)) {
field.setValue((String)employeeData.get(partialName));
}
4. Save PDF: Creates `pdfs` folder if it doesn't exist and saves PDF document there. It checks for the folder, creates it if necessary, and saves the PDF to the specified path, ensuring proper storage.
String targetFolder = "pdfs";
File folder = new File(targetFolder);
if (!folder.exists()) {
folder.mkdirs();
}
File savedFile = new File(folder, filename);
document.save(savedFile.getAbsolutePath());
You can verify the creation of the `pdfs` folder within the Java project structure by viewing it in your IDE.
IV. Working with Multiple Pages and Variables in PDF Templates
Assuming that an employee's name needs to be placed in multiple locations on a single page, you will see that AEM Forms Designer automatically appends indices to the partial names, such as employee_name[0], employee_name[1], etc., to differentiate between the fields. This indexing allows us to map data from the REST API to the PDF template accurately.
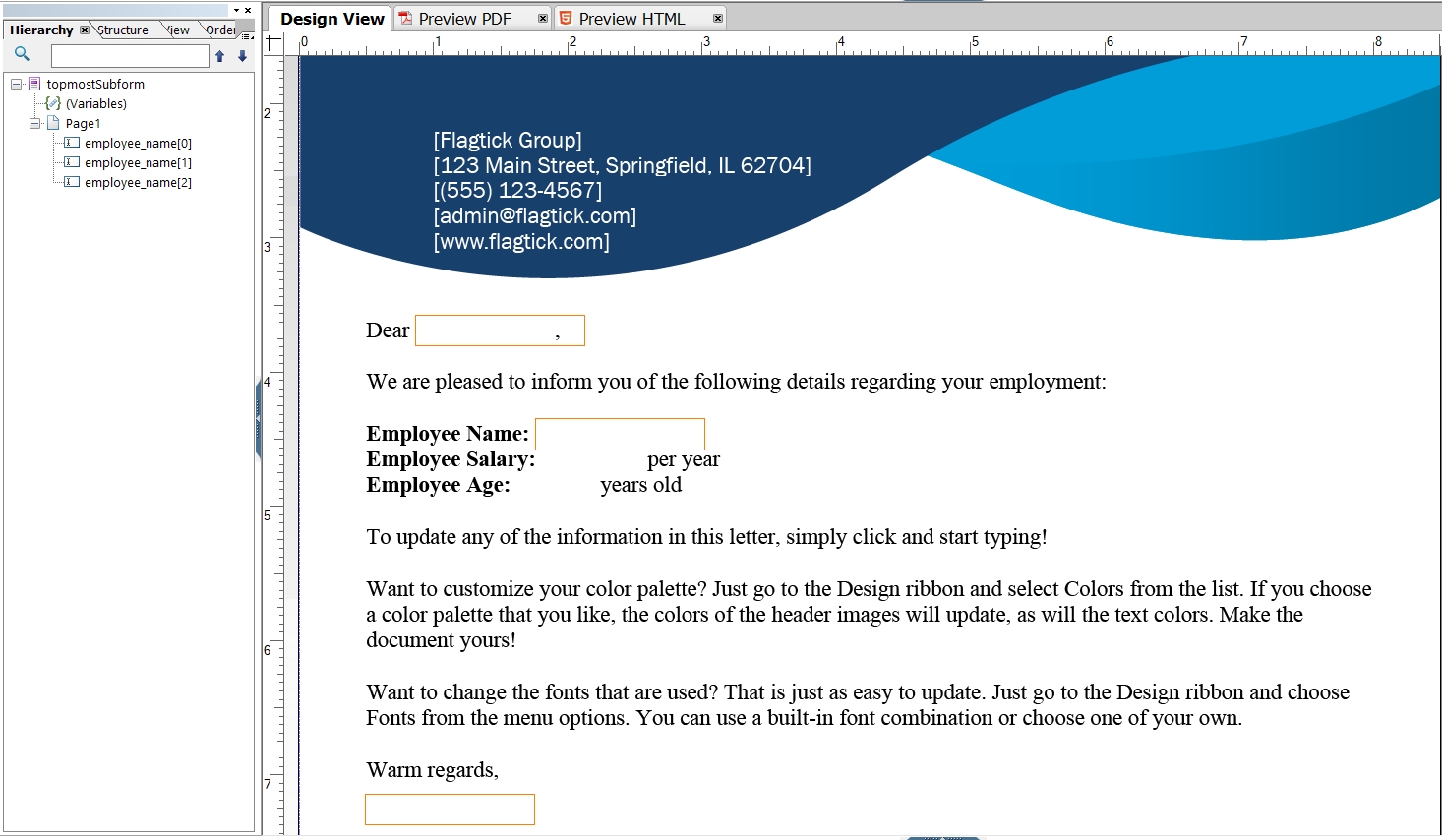
In AEM Forms Designer, if you display the employee name in multiple locations on a single page, you need to account for automatically generated indices in the partial names to differentiate between these fields.
Here is an example code that implements the changes described above.
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpGet request = new HttpGet("https://dummy.restapiexample.com/api/v1/employee/1");
HttpResponse response = httpClient.execute(request);
HttpEntity entity = response.getEntity();
String result = EntityUtils.toString(entity);
ObjectMapper mapper = new ObjectMapper();
SimpleModule module = new SimpleModule();
module.addDeserializer(Map.class, new EmployeeDeserializer());
mapper.registerModule(module);
Map<String, Object> employeeData = mapper.readValue(result, Map.class);
System.out.println("Original Employee Data:");
System.out.println("Employee Name: " + employeeData.get("employee_name"));
System.out.println("Employee Salary: " + employeeData.get("employee_salary"));
System.out.println("Employee Age: " + employeeData.get("employee_age"));
HashMap<String, String> transformedEmployeeData = new HashMap<>();
int nameIndex = 0; // Index for employee_name (0 to 2)
int salaryIndex = 0; // Index for employee_salary (only 0)
int ageIndex = 0; // Index for employee_age (only 0)
for (Map.Entry<String, Object> entry : employeeData.entrySet()) {
String originalKey = entry.getKey();
String newKey = "";
if (originalKey.equals("employee_name")) {
newKey = "employee_name[" + nameIndex + "]";
nameIndex++;
if (nameIndex > 2) {
nameIndex = 2;
}
} else if (originalKey.equals("employee_salary")) {
newKey = "employee_salary[" + salaryIndex + "]";
salaryIndex++;
} else if (originalKey.equals("employee_age")) {
newKey = "employee_age[" + ageIndex + "]";
ageIndex++;
}
if (!newKey.isEmpty()) {
transformedEmployeeData.put(newKey, String.valueOf(entry.getValue()));
}
}
// Clear and update the original map with transformed data
employeeData.clear();
employeeData.putAll(transformedEmployeeData);
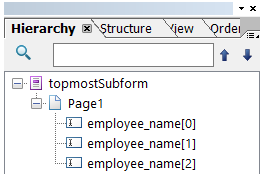
In the other hand, if you need to place an employee name field on multiple pages, you can assign the partial name `employee_name` to each instance. This setup assumes that each `employee_name` field is correctly positioned and mapped across pages, with the understanding that the index is implicitly set to 0.
V. Refactoring Java Classes for SRP Using Design Patterns
Learn how to refactor Java classes to adhere to the Single Responsibility Principle (SRP) by utilizing design patterns. Enhance your code quality and maintainability with these best practices.
» App.java
public class App {
private static final Logger LOGGER = LoggerFactory.getLogger(App.class);
public static void main(String[] args) {
try {
PropertiesLoader propertiesLoader = new PropertiesLoader();
Properties prop = propertiesLoader.loadProperties("application.properties");
TemplateTaxLoader templateTaxLoader = new TemplateTaxLoader();
Map<String, String> templateTaxes = templateTaxLoader.loadTemplateTaxes(prop);
EmployeeService employeeService = new EmployeeService();
Map<String, Object> employeeData = employeeService.getEmployeeData("https://dummy.restapiexample.com/api/v1/employee/1");
PDFProcessor pdfProcessor = new PDFProcessor();
pdfProcessor.processPDF(templateTaxes, employeeData);
LOGGER.info("Templates loaded successfully: {}", templateTaxes);
} catch (IOException e) {
LOGGER.error("Error loading application.properties", e);
}
}
}
» PropertiesLoader.java
public class PropertiesLoader {
private static final Logger LOGGER = LoggerFactory.getLogger(PropertiesLoader.class);
public Properties loadProperties(String fileName) throws IOException {
try (InputStream input = getClass().getClassLoader().getResourceAsStream(fileName)) {
if (input == null) {
LOGGER.error("Sorry, unable to find " + fileName);
throw new FileNotFoundException("File not found: " + fileName);
}
Properties prop = new Properties();
prop.load(input);
return prop;
}
}
}
» TemplateTaxLoader.java
public class TemplateTaxLoader {
public Map<String, String> loadTemplateTaxes(Properties prop) {
Map<String, String> templateTaxes = new HashMap<>();
String templates = prop.getProperty("templates");
if (templates != null && !templates.isEmpty()) {
for (String kv : templates.split(",")) {
String[] a = kv.split(":");
if (a.length == 2) {
templateTaxes.put(a[0], a[1]);
}
}
}
return templateTaxes;
}
}
» EmployeeService.java
public class EmployeeService {
public Map<String, Object> getEmployeeData(String url) throws IOException {
CloseableHttpClient httpClient = HttpClients.createDefault();
HttpGet request = new HttpGet(url);
HttpResponse response = httpClient.execute(request);
HttpEntity entity = response.getEntity();
String result = EntityUtils.toString(entity);
ObjectMapper mapper = new ObjectMapper();
SimpleModule module = new SimpleModule();
module.addDeserializer(Map.class, new EmployeeDeserializer());
mapper.registerModule(module);
return mapper.readValue(result, Map.class);
}
}
» PDFProcessor.java
public class PDFProcessor {
private static final String FT_TEXT_FIELD = "Tx";
public void processPDF(Map<String, String> templateTaxes, Map<String, Object> employeeData) {
HashMap<String, String> transformedEmployeeData = new HashMap<>();
for (Map.Entry<String, Object> entry : employeeData.entrySet()) {
String originalKey = entry.getKey();
String newKey = originalKey + "[0]";
transformedEmployeeData.put(newKey, String.valueOf(entry.getValue()));
}
employeeData.clear();
employeeData.putAll(transformedEmployeeData);
String template = templateTaxes.get("2023");
System.out.println("Template: " + template);
try {
URL res = getClass().getClassLoader().getResource(template);
if (res == null) {
System.out.println("Resource not found: " + template);
return;
}
File file = Paths.get(res.toURI()).toFile();
PDDocument document = Loader.loadPDF(file);
try {
PDAcroForm acroForm = document.getDocumentCatalog().getAcroForm();
if (acroForm != null) {
PDFieldTree fieldTree = acroForm.getFieldTree();
for (PDField field : fieldTree) {
String fullyQualifiedName = field.getFullyQualifiedName();
String partialName = field.getPartialName();
String fieldType = field.getFieldType();
System.out.println("Field name: " + fullyQualifiedName);
System.out.println("Field Partial Name: " + partialName);
System.out.println("Field type: " + fieldType);
System.out.println("Field class: " + field.getClass().getSimpleName());
if (fieldType != null && fieldType.equals(FT_TEXT_FIELD) && employeeData.containsKey(partialName)) {
field.setValue((String) employeeData.get(partialName));
}
}
acroForm.flatten();
} else {
System.out.println("The PDF does not contain any form fields.");
}
String filename = UUID.randomUUID() + ".pdf";
// Define the target folder relative to your project root
String targetFolder = "pdfs";
File folder = new File(targetFolder);
if (!folder.exists()) {
folder.mkdirs();
}
File savedFile = new File(folder, filename);
document.save(savedFile.getAbsolutePath());
} finally {
document.close();
}
} catch (IOException | URISyntaxException e) {
System.out.println("Exception: " + e.getMessage());
e.printStackTrace();
}
}
}
VI. Conclusion
This article aims to help you understand how to use AEM Forms Designer tool, Microsoft Word, and Apache PDFBox to create a comprehensive solution for generating PDFs and dynamically mapping data from a REST API or any data warehouse.
With this solution, you can implement it as a serverless application using AWS Lambda to associate with AWS S3 and RDS, allowing you to generate PDFs dynamically.
If you have any questions while following the article, feel free to reach out to us via email at [email protected] or GitHub link here or leave a comment.
VII. Video



